
")
Volpara has entered into a Scheme Implementation Agreement with Lunit, Inc.
What do I need to know about my breast composition?
Breasts are composed of dense (fibrograndular) and fatty (adipose) tissue. Your mammogram report categorizes your breast tissue into a density category: dense or non-dense. These two categories can be further broken down into smaller categories labeled A, B, C, or D, where categories A and B indicate breasts as non-dense and categories C and D indicate breasts as dense.
- Having more dense tissue in your breasts (category C or D) is common – this is the case for nearly half of the women over the age of 40 in the United States.1
- Dense tissue can camouflage cancer on the mammogram and increase your risk of developing cancer in your lifetime.
- More screening in addition to a mammogram should be considered for women with dense breasts.
- For women with less breast density, regular mammogram screening is still essential for early detection of cancer.
Breast density and risk — why it’s important
Women with dense breasts may have a higher risk of breast cancer and it is also harder to detect cancer in dense breasts.
The star shows how an early stage cancer may look.

The star shows how an early stage cancer may look.
The star shows how an early stage cancer may look.
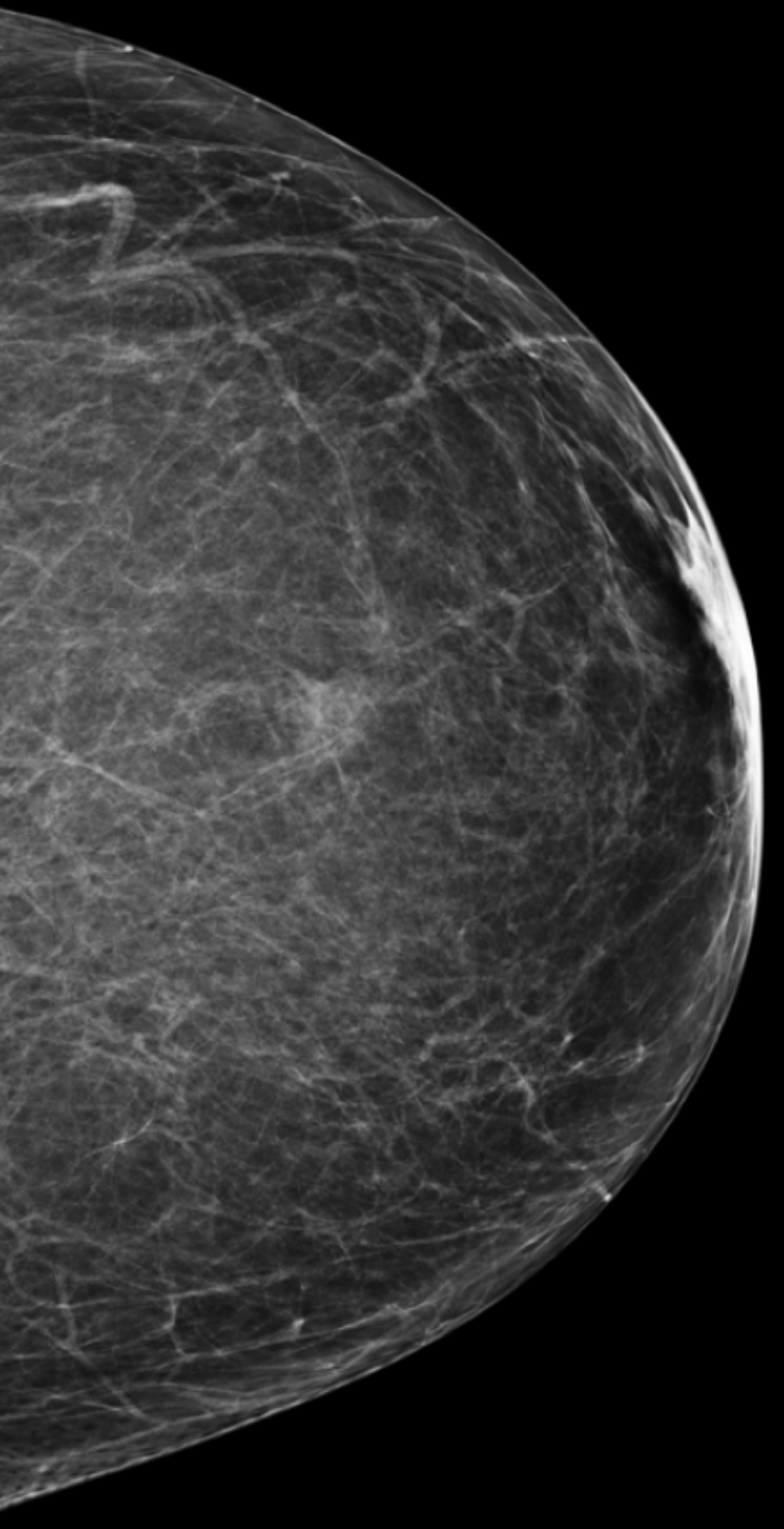
A
Low tissue density
Almost entirely fatty
Your mammogram displays mostly fatty tissue, which appears as dark gray, combined with minor areas of white and light gray fibroglandular tissue. Your breasts are not considered dense.
About 10% of female breasts fit category “A”. They are referred to as “fatty breasts”.1
If you are over the age of 40 and in good health, an annual mammogram is recommended.2 Also consider asking your doctor about a risk assessment to help both of you better understand your lifetime risk for breast cancer.
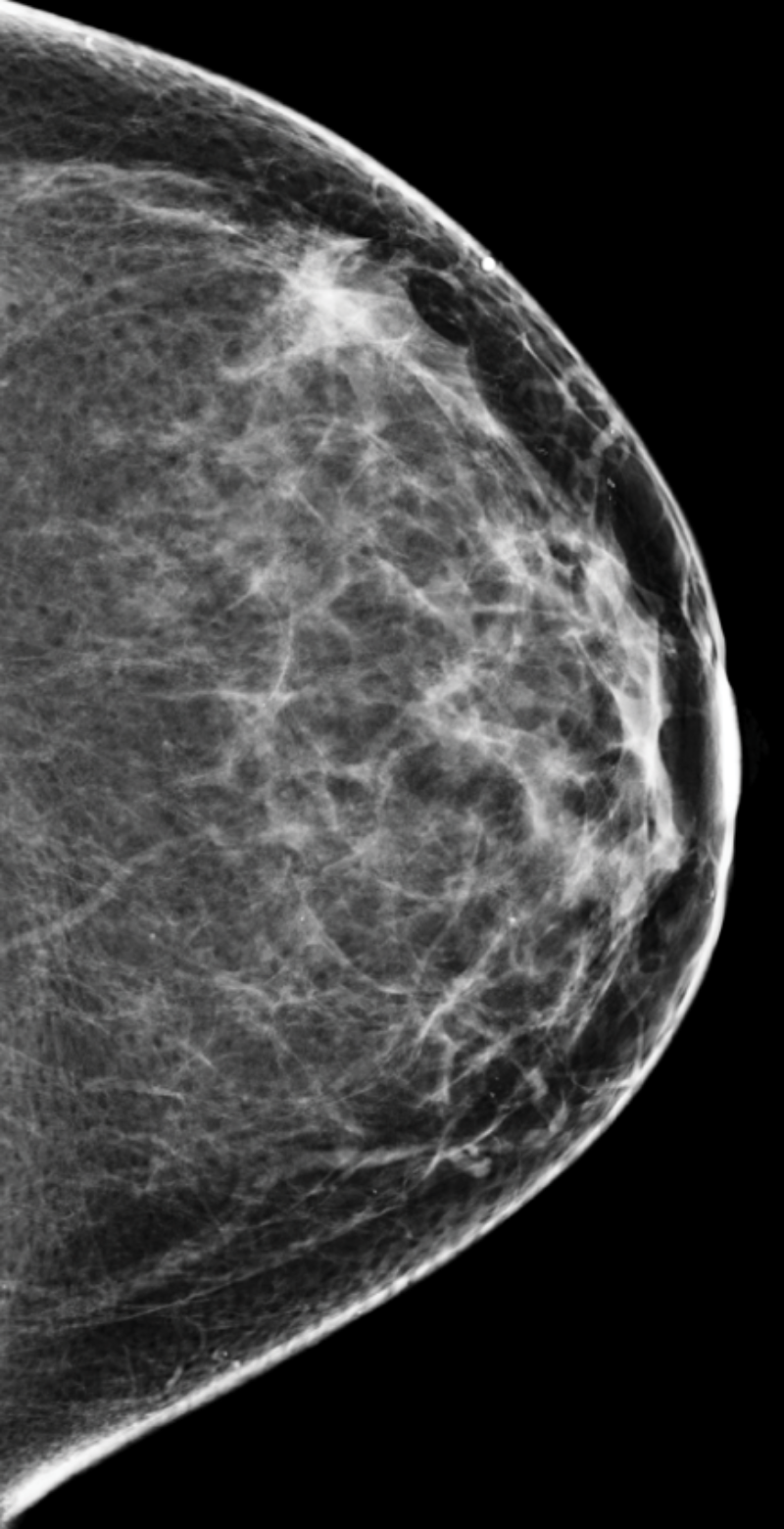
B
Low-mid tissue density
Scattered areas of density
Your mammogram displays mostly fatty tissue, which appears as dark gray, combined with scattered areas of white and light gray fibrograndular tissue. Your breasts are not considered dense.
About 40% of female breasts fit category “B”. They are referred to as breasts with “scattered areas of fibroglandular density”.1
If you are over the age of 40 and in good health, an annual mammogram is recommended.2 Also consider asking your doctor about a risk assessment to help both of you better understand your lifetime risk for breast cancer.
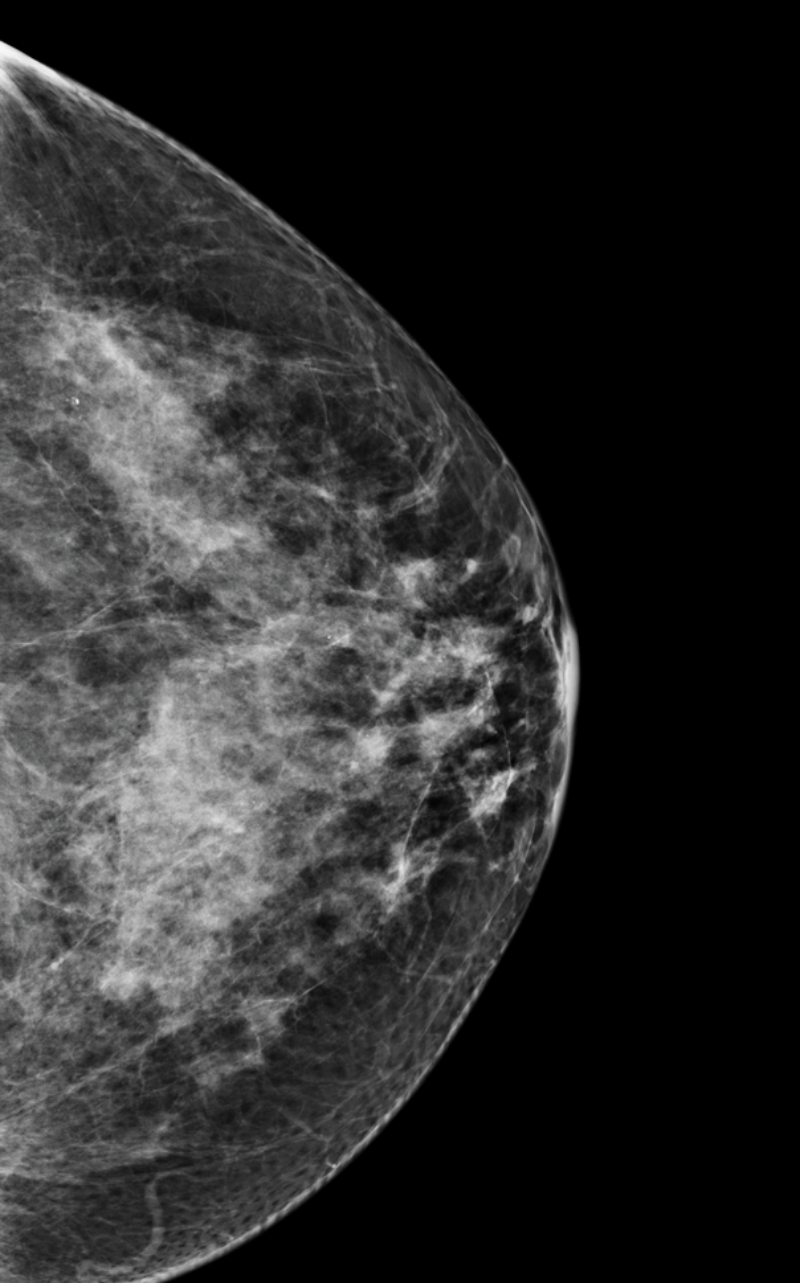
C
Mid-high tissue density
Heterogeneously dense breasts
Your mammogram displays mostly dense, fibroglandular tissue, which appears white and light gray, combined with lesser areas of dark gray fatty tissue. Your breasts are considered dense.
About 40% of female breasts fit category “C”. They are referred to as “heterogeneously dense breasts”.1
Your dense tissue could hide masses on your mammogram.3 Consider asking your doctor if additional ultrasound or MRI imaging should become part of your screening schedule. Also consider asking about a risk assessment to help both of you better understand your lifetime risk for breast cancer.
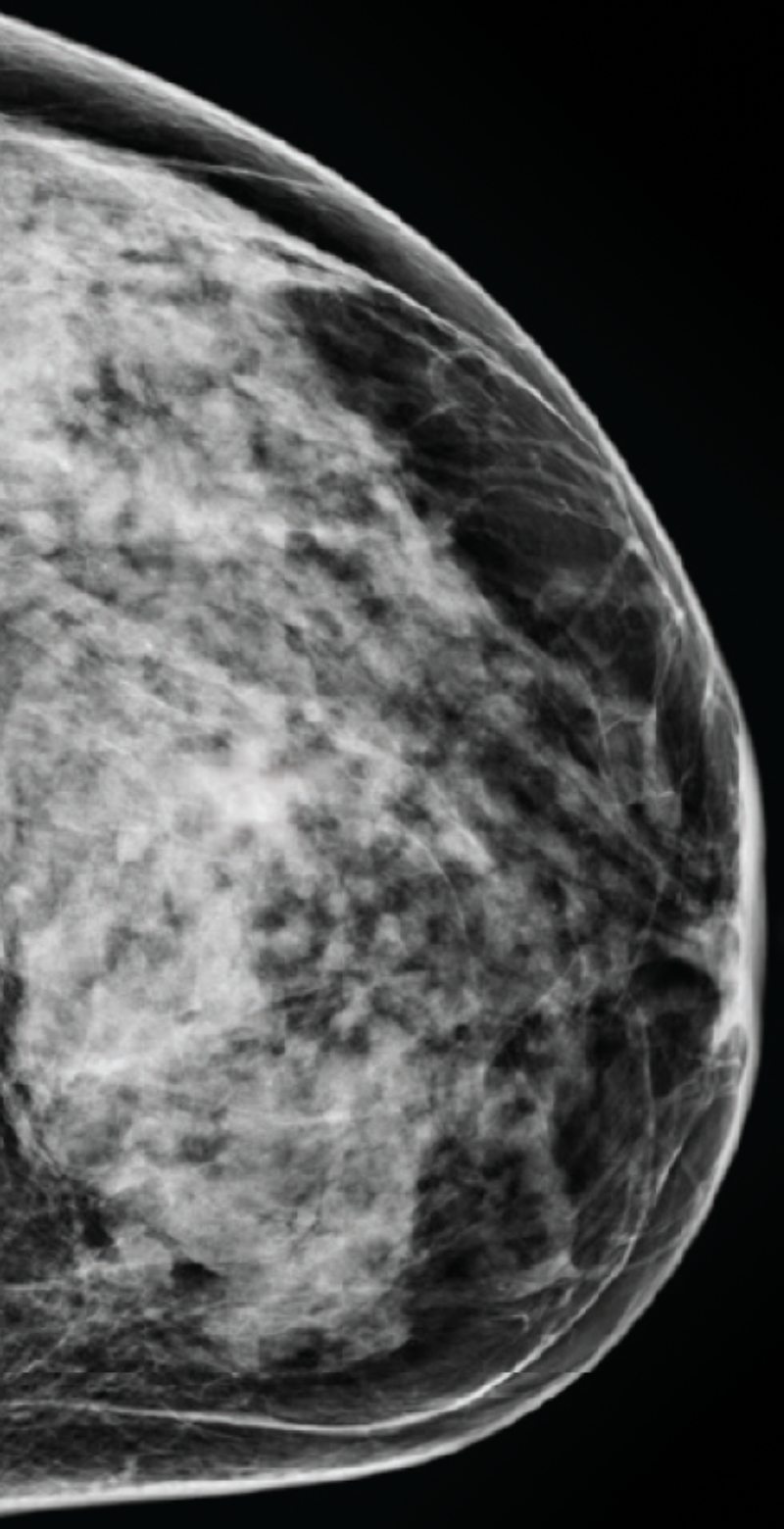
D
High tissue density
Extremely dense breasts
Your mammogram displays mostly dense, fibroglandular tissue, which appears white and light gray, combined with very little dark-gray fatty tissue. The large amount of white areas makes it difficult for a radiologist to confidently rule out that cancer is not present. Your breasts are considered dense.
About 10% of female breasts fit category “D”. They are referred to as “extremely dense breasts”.1
Women with high breast density may have a greater risk of developing breast cancer. High breast density also makes it harder to detect breast cancer.3 Consider asking your doctor about adding ultrasound and/or MRI imaging to your screening schedule. Also consider asking about a risk assessment to help both of you better understand your lifetime risk for breast cancer.
Have questions? Learn more here.
1. https://www.mayoclinic.org/tests-procedures/mammogram/in-depth/dense-breast-tissue/art-20123968#:~:text=Extremely%20dense%20indicates%20that%20nearly,10%20women%20has%20this%20result.
2. https://www.acraccreditation.org/mammography-saves-lives/guidelines
3. https://www.cancer.org/cancer/breast-cancer/screening-tests-and-early-detection/mammograms/breast-density-and-your-mammogram-report.html
Disclaimer: The content on this site is for informational purposes only. The content is not intended to be medical advice, diagnosis, or treatment, or a substitute for such advice, diagnosis, or treatment. You should always consult with your healthcare provider for medical advice, diagnosis, and treatment, including your specific medical needs. Volpara Health does not recommend or endorse any specific methods of supplemental screening or treatment.